
The pros and cons of implementing Jenkins pipelines
With multibranch pipelines, Jenkins has entered the battle of the next generation CI/CD server. But with contestants such as Concourse and CircleCI, there is no clear winner.
Praqma has been working with Jenkins (née Hudson) as the de facto continuous integration server for nearly a decade now. And for a long time, Jenkins leadership was unchallenged. But recently a plethora of competitors have entered the scene, giving good ol’ Jenkins a run for its money. To combat this, Jenkins has introduced pipelines: a Groovy DSL to control your CI flow by code. With CloudBees investing heavily in pipelines, it has become the future of Jenkins. If you haven’t looked at it yet, go visit the Jenkins pipeline page
So should you just convert all your jobs to pipeline, and then live happily ever after? The answer is, as it is in almost any other aspect in life; it depends.
This post shows examples using the Phlow and Praqma’s Pretested Integration Plugin. If you do not know about it, go educate yourself.
The Story
At one of our customers we wanted to create a pipeline that built on multiple OSes in parallel. The solution should block the integration job until all compilation and unit test was done. The original pipeline was made through the Jenkins UI, so we needed to make it as code one way or another. No more pointy pointy, clicky clicky!
 We could either convert the existing solution to JobDSL, or try to make a Jenkins pipeline version of the same build flow. We went for Jenkins pipelines in order to gain some of the benefits listed in our slide deck on future pipelines.
We could either convert the existing solution to JobDSL, or try to make a Jenkins pipeline version of the same build flow. We went for Jenkins pipelines in order to gain some of the benefits listed in our slide deck on future pipelines.
To multibranch or not to multibranch, that is the question!
Pipeline jobs come in two variants; normal and multibranch. Common to both of them is the language; a Groovy based DSL.
We went with the multibranch pipeline, as it accomplishes having the pipeline embedded as code in the same repository (usecase #1 in the slide deck above). Also, in standard pipeline, there is no way of knowing which branch activated the build, as Jenkins checks out a SHA, not a branch.
A reduced example of the pipeline in production can be found here.
How to implement the Phlow in Pipeline
As Praqma’s current version of Pretested Integration Plugin isn’t Pipeline compatible, we needed to script us to the same functionality. I will not go through the pipeline script, but talk about the problems we ran into when developing the script.
Git publisher much?
As pipelines is a new way of interacting with Jenkins, you cannot leverage all the plugins and functions that a normal freestyle job offers.
For example, the Git checkout routine can be used for the cloning part of pretested integration, but when we need to push the code back to a branch there is no help.
An issue is raised concerning this, but until it is resolved, you need to use bare Git commands wrapped in the sshagent plugin.
Overview is dead, long live the overview
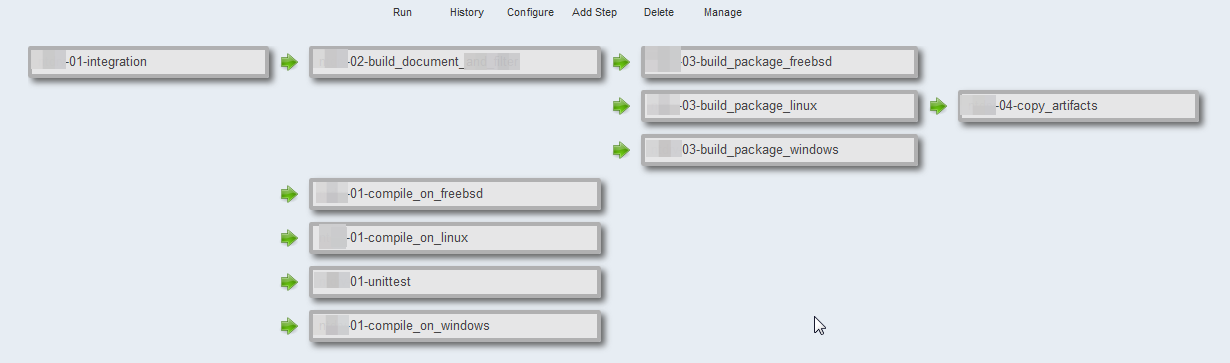
As illustrated below, the old freestyle jobs can easily be made into an overview when set to trigger one another.
The overview gives a good glance at which branch is building right now and you can identify any persistent errors in a pipeline by scrolling down the list of executions.
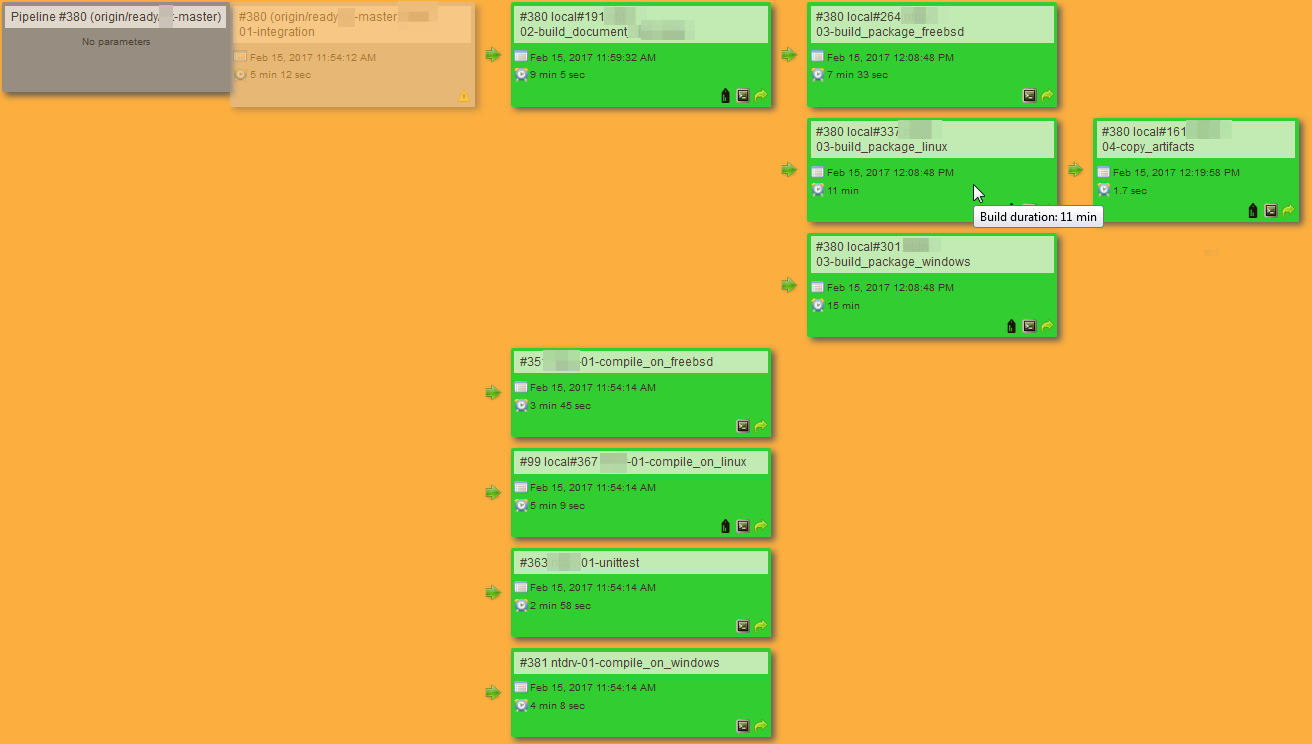
With Jenkins Pipeline, the per-master view approach we can take with PIP and freestyle jobs is lost. The overview is repository-centric, meaning all branches are treated equal, resulting in one view for all branches. To give an example, both the master and /version_2.x/master will now be in the same view.
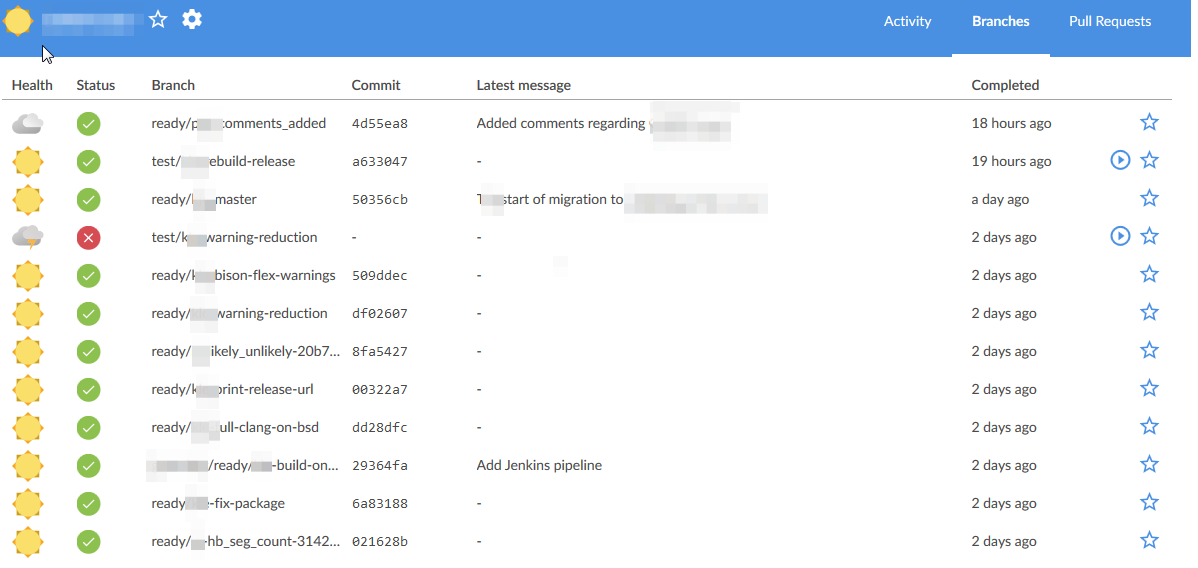
When going into the individual build, we get a much better overview of parallel builds and easy navigation to the relevant output than what the old style overview did. Each icon is clickable, and shows you the list of commands and corresponding logs.
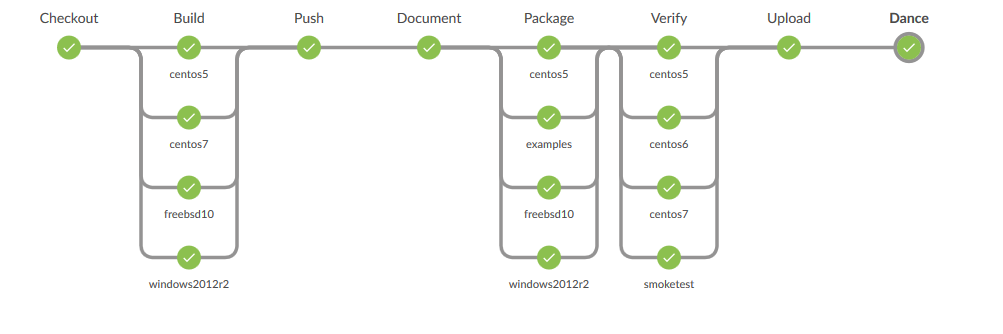
So if this is a must have feature, you need to make some kind of dashboard that can give some of the same information as the old way (look at dashing.io or Pipeline Aggregator View).
Another way is to split the pipeline in two parts:
- One finding out if the pretested integration went good or bad
- One building the master pipeline (everything after the toll gate described in our CoDe Storyline)
That way you get the per-master spilt you want, but sacrifice the whole traceability by developer commit.
A deleteDir() a day keeps the doctor away
Unless you have multiple stages running on the same node at the same time, you do not get a new workspace. It automatically reuses the old.
This results in a lot of deleteDir() in your pipeline. Otherwise you get wired errors when stashing and unstashing.
You can wrap your node inside a function to make sure that you always have a clean workspace.
Let’s take it from the top

Retriggering a pipeline from a given job is again easy in freestyle jobs.
When dividing everything into individual jobs, we have the possibility to retrigger a given pipeline from a specific point.
When using Jenkins Pipeline, it’s all or nothing, making it impossible do a retrigger with PIP, as you do not want to retrigger the integration step.
CloudBees has made a propritary plugin called checkpoints. It allows you to restart at that checkpoint. Unfortunately, they did not open source it or close any issues highlighting this .
That is also an argument for splitting the pipeline in two; one for integration to master, the other for the build pipeline itself.
Manual baby steps, with pitfalls
If you need to perform some manual validation before proceeding to the next stage in your pipeline use the input tag in your Jenkinsfile. If it’s only a signal, put it on a flyweight executor so it doesn’t take up an executor slot on a node.
stage 'Promotion' { input 'Deploy to Production?' }There are some disadvantages to this workflow. In the Jenkins UI it looks like the pipeline is still executing even though it is waiting for manual input. I would have loved to see it parked instead of actively still running. But that is what we got for now.
Conclusion
Jenkins Pipelines is definitely a step in the right direction, and I must be totally honest with you; I like it, but I also see problems!
It is not more than a month ago that Jenkins removed the ‘BETA’ tag from Blue Ocean, the new UI that matches Pipelines.
Some of the problems described here could be solved a year from now, and some of the things we just learn to deal with in more elegant ways.
To sum up the experience, here is a TL;DR of the pros and cons discussed above:
Pros:
- The ability to specify the pipeline inside your SCM repository; pipeline as code!
- New pipeline is just a new branch, and you’re ready
- Your pipeline is not only treated as code, it is code!
- Stashing guarantees that parallel builds run the same code.
- Pipeline is the future of Jenkins. Adapt like the best or die like the rest.
Cons:
- No Pretested Integration Plugin available
- Git SCM functionality is reduced to bare Git commands
- No overview for a manager if pipeline is full
- No overview for a developer if pipeline is cut in two.
- No ability to re-run parts of the pipeline
/readybranches are deleted in the overview after they are run (and merged)
Published: May 9, 2017
Updated: Dec 5, 2024
