
How to make the right technical choices on your cloud native journey
When you embark on your cloud native journey there will be important choices to make about cloud providers, continuous deployment, environments’ setup and separation. This guide will help you make the right choices by sharing lessons learnt from running cloud native apps in production.
Kubernetes has become the de facto container orchestration platform. When we help clients of different sizes and domains start their cloud native journeys in Kubernetes, we assist them in making sound decisions and technology choices. There is no one-size-fits-all solution when it comes to choosing cloud providers, CI tools, continuous deployment pipelines etc., so it is important to make the right decisions at the start. Failing to do so can be very costly in terms of lost time and money.
In this blog we share some of the important considerations you will face when making decisions and technical choices to get started in Kubernetes. This post targets anyone who is starting their cloud native and Kubernetes path, but also anyone who has already started and wants to verify their choices.
Choose the right platform
Kubernetes clusters can be self-managed or managed by a cloud provider. The rule of thumb is to use a managed Kubernetes service unless you have a sound technical or legal reason to use an on-prem self-managed cluster. Self-managed clusters require highly specialized competence within your team and ongoing infrastructure and maintenance costs.
If you choose to go with a managed Kubernetes service make sure you choose the right provider. This depends on several factors, including:
- Familiarity with the provider’s services among your team.
- Maturity of the provider’s managed Kubernetes offering and the features and technical limitations they have. For example, whether regional redundancy or cluster autoscaling is supported. Another example is whether pod security policies and network policies are supported.
- Whether you need to use other cloud services from the same provider. For example, if your application requires a DynamoDB database from AWS, then it makes sense to use AWS EKS in the same region as your DynamoDB database to reduce data access latency.
- Pricing, SLA, and support packages offered by the provider.
Generally speaking, if you need a simple Kubernetes cluster you’ll be fine using one of the three big cloud providers: AWS, Google, or Azure. However, in our experience, Google’s GKE is the simplest to start with and the most mature managed Kubernetes offering in the market.
Decide how to split your environments
Most of the time, you will have at least two environments: dev/test and prod. How should those be split in Kubernetes? You can either have one cluster per environment or a namespace per environment. While using namespaces to split environments reduces costs by sharing the same infrastructure, it is more risky because of the expected human errors from developers and operators. Avoiding such errors and access issues is possible but requires high competence within the team to implement and monitor. There is a trade-off between infrastructure cost and the man-power needed for access control and security.
Having a cluster per environment is what we recommend for small teams.
You could also place the clusters in separate virtual/physical networks and/or separate cloud projects/accounts. This offers a clearer separation that makes it easy to maintain strict access to prod environments while also allowing for experimentation on the Kubernetes setup itself in the dev cluster. This makes it safe to enable certain Kubernetes features or to test newer Kubernetes versions.
Standardize your k8s setup
Once you have chosen a platform to deploy your Kubernetes clusters on the question becomes how do you deploy and maintain your clusters? In most cases you will have to manage more than one cluster, and it is important to avoid configuration drifts between them. For example, you may have dev and prod clusters and you want to make sure that they both have the same configurations and their nodes have the same access/auth scopes to other cloud services. This is important because you will be promoting your application deployed in dev to be deployed in prod and you won’t want to have any bad surprises.
To do this, we recommend using an infrastructure-as-code approach where you define the cluster configuration as code and maintain these configurations in a version control system. When you have your cluster config as code, you can spin up a new identical cluster to test something new without even disrupting developer workflow.
We also recommend using a pipeline to deploy and maintain your clusters based on changes in your version-controlled configurations. This is often referred to as GitOps.
Treat utilities as infrastructure
Utilities are third party tools/services that you deploy in your cluster. This can be monitoring tools like Prometheus or SSL certificates manager like cert-manager. These utilities should be treated as part of the infrastructure i.e. they are deployed from code when the cluster is created, and are maintained through a pipeline similar to the cluster itself. It could even be a separate job in the same pipeline which creates the cluster. The advantage of this is that you can easily recreate/replicate the cluster with all its third party utilities. Our own open source tool Helmsman can be used to orchestrate deployment of third party utility apps.
Good use of namespaces
Kubernetes namespaces are virtual dividers within a single cluster. They are often used to separate teams and applications. When using namespaces consider the following:
- In a multi-tenant cluster give developers access to only the namespaces they need by utilizing Kubernetes RBAC.
- Secrets are namespaced objects and cannot be accessed from another namespace. If several applications deployed in different namespaces require access to the same set of secrets you will have to either: a) deploy these apps in the same namespace, b) replicate the secrets across namespaces and keep them in sync manually, or better yet, c) use a secrets management utility like Vault.
- You can set resource quotas per namespace. Thus, setting limits per team or per sets of applications.
- You can use network policies) to allow or block traffic between apps deployed in different namespaces.
- Kubernetes resource names (e.g. deployments, pods, etc) are unique within a namespace, so you either deploy different versions of the same app in different namespaces or make your resource names dynamic, which can be done when you package your app using Helm.
Helm deployment
Helm is the package manager for Kubernetes. It is a useful tool to package and share your configurable application Kubernetes deployment templates. We recommend using Helm over using plain Kubernetes yaml templates to deploy your applications. Helm packages -aka charts- allow reusing templates with configuration parameters. This makes it easy to deploy multiple instances of your application in different environments with different configurations without redundant code or templates.
Helm 2.x requires a server-side component called Tiller to be deployed in the cluster. Helm 3.0 will remove Tiller, but it is currently an alpha release. As you use Helm 2.x for the time being, you will have to think about how to deploy and secure your Tiller. Consider the following:
- Tiller will have full access to the cluster. So make sure to follow the recommended security configurations when deploying it.
- We recommend having Tiller deployment as part of your cluster pipeline. This is useful when you want to replicate the cluster setup, or for disaster recovery. Our open source tool Helmsman can be used to deploy secure Tiller(s).
- In a multi-tenant cluster deploy a Tiller per team in their namespace and configure RBAC to limit Tiller’s scope to that namespace only.
Continuous Deployment (CD) of Applications
Frequent application releases are considered a good practice because it correlates with lowering the risks of failure and speeding incident recovery time (source: The state of DevOps report 2019). When using Kubernetes and Helm you should have an automated pipeline to continuously deploy your changes to K8S.
Figure 1 illustrates a typical CD pipeline for cloud native apps deployed in K8S.
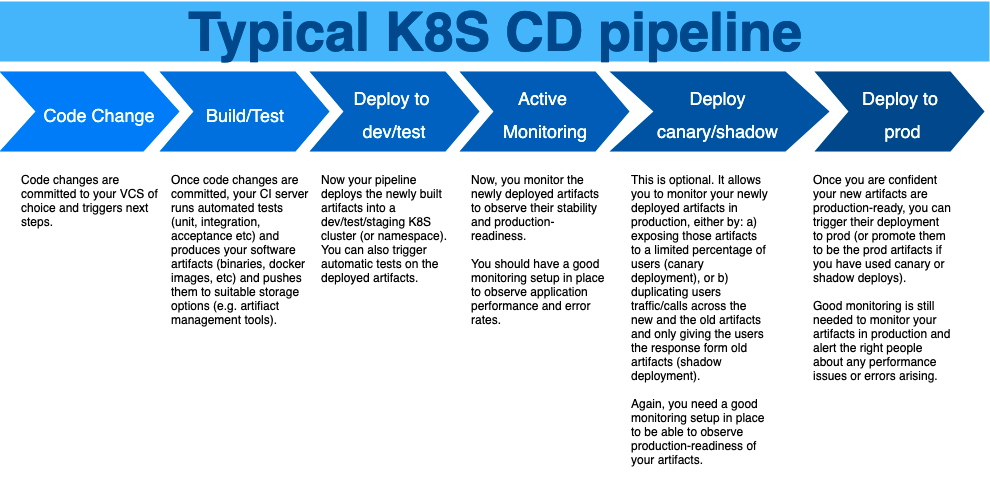
When designing your pipeline think about how you want to promote your application from the dev/test environment to the prod environment. This could be done with manual approvals in a single pipeline or you can split the dev and prod pipelines. There is no one-size-fits-all solution, but always try to use the simplest pipeline configuration until you have good reasons to make it more complex. Additionally, keep in mind developer convenience when designing the workflow. For example, if a developer has to make changes in multiple repos to get their small bug fix into prod, that’s probably not convenient enough to encourage faster and frequent deploys!
Helm charts and repos
When packaging your applications as Helm charts consider the following:
- If several applications/services have an identical or very similar Kubernetes deployment templates (e.g. a deployment, service and an ingress), then make a shared chart that is configurable to cater for all of these applications. This lets you focus on and harden a single chart instead of many similar charts.
- How to manage your helm charts? And how will you share them internally or externally if needed?
Another aspect to consider is where will you store your helm charts and how will you use them. Three patterns are commonly used:
1) Have your helm chart directory as part of your application VCS repo.
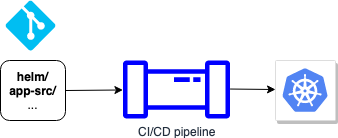
The benefits of this approach is that you have everything in one place. However, the drawbacks include:
- complex plumbing in your pipeline to version and publish the chart separately from the app (unless you decide to release the chart and the app together every time, even though the chart may not have actually changed.)
- If other apps (in other VCS repos) are deployed with the same chart you will have redundant code across your repos.
- You can’t share your chart without giving access to your application VCS repo.
2) Have a separate VCS repo for Helm charts and serve them from a Helm repo.
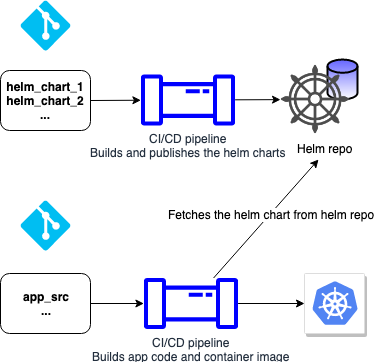
The pros of this approach include:
- Versioned charts that are served from public or private Helm repos.
- The ability to use the same chart for multiple apps where suitable without code duplication.
The biggest downside of this approach is that when your application changes in a way that requires a change in the Helm chart, you would have to make the Helm chart change separately at first, then deploy the application code change.
3) Since chart changes will be frequent in the early stages of application development you can combine approaches 1 and 2 at different stages of your application development. The first approach can be used at the start and once the application stabilizes the second approach can be used.
While the patterns above are viable in different cases your choice should be based on your use-case and weighing up the pros and cons of each.
Cluster state maintenance
It is important that you plan for failure. And you should think about scenarios like: what happens when applications are deleted ? Or, what happens if the cluster is deleted altogether? What if we want to create an identical copy of the cluster in a different cloud region?
To be ready for all these scenarios you need to backup and store the cluster state somewhere safe. Luckily, there are tools that can help you with that. We have been successfully using Velero from VMWare. Velero allows you to setup a regular backup of the cluster state (deployments, volumes,etc.) and store it in cloud storage. The cluster snapshots can be used to restore the cluster state at any time. But what if we need to recreate the cluster itself? If you deploy the cluster from code, as we discussed above, then you can recreate the cluster using the same version-controlled code you used to create it in the first place, and then restore its state using a Velero snapshot.
Final word
It is easy and tempting to make shortcuts when you are getting started. That’s fine when you are in the learning and experimenting phase. However, once you start setting up your Kubernetes environments, make sure that you do the right thing from the start even if it means more time and effort. It will pay off in the future!
Published: Aug 16, 2019
Updated: Mar 26, 2024
